

Architektura otwartych bibliotek obrazków & wulkanów by @natur
//tekst popełniony przez @natur;
//mam nadzieję, że nie pokićkałem obrazków, gdyż narzędzie toporne;
Architektura OpenGL / Vulkan na różnych systemach
Spis treści
1. Kim jestem?
2. Wprowadzenie
3. Architektura OpenGL na Linuxie
4. Współpraca EGL z kompozytorem
5. Architektura OpenGL w wirtualnych maszynach
6. Architektura OpenGL na Androidzie
7. Architektura OpenGL w Safety Critical systemach
1. Kim jestem?
Dzień dobry! Od dawna jestem czytelnikiem tego bloga. Czasami się udzielam na forum, ale wolę czytać komentarze mądrzejszych ode mnie. Zawodowo jestem związany z IT. Od 12 lat pracuję w różnych korporacjach, które dostarczają na rynek różne akceleratory. Tak się złożyło, że przez większość czasu poświęciłem na akceleratory 3D, chociaż był okres, podczas którego pisałem sterowniki dla Sztucznej Inteligencji. Jako Software Engineer piszę sterowniki OpenGL / Vulkan dla Intela, AMD i innych.
Po co jest ten artykuł?
Po 12 latach i przepracowania w różnych firmach chciałem podsumować swoją wiedzę. Nie było moim celem szerzenie wiedzy, tylko poukładanie wszystkiego w swojej głowie.
Tutaj dotknę tylko i wyłącznie niektóre aspekty architektury sterowników 3D. Jeśli powstaną pytania, to chętnie rozwinę jakieś aspekty.
2. Wprowadzenie
Czym jest grafika 3D? Jak to się dzieje, że biorąc telefon do ręki i włączając go, jest wrażenie, że przyciski są 3D, że animacja jest płynna, są wodotryski i ogólnie wydaje się, że telefon „żyje”. Każda animacja 3D wymaga przeliczenia. Ogólnie rzecz biorąc pixel na ekranie – jego kolor – musi być przeliczony. Jeśli mamy obiekt, który ma swoje wymiary i współrzędne oraz chcemy go narysować na ekranie, to musimy przeliczyć te współrzędne z lokalnych na globalne (mnożenie przez macierz dla każdej współrzędnej), zrobić rzut przeliczonego obiektu na ekran i go pokolorować. Jeśli to jest pojedynczy trójkąt, to nie jest to skomplikowane, gorzej jest jeśli to jest gra strzelanka i mamy mnóstwo obiektów na ekranie, gdzie każdy się składa z milionów poligonów i rozdzielczość ekranu może być kosmiczna do pokolorowania. Można to robić na CPU, nie ma problemu. Problem jest taki, że to zajmuje dużo czasu, a my chcemy szybciej, więcej! Dlatego powstały akceleratory do obliczeń 3D, potocznie zwane GPU – graphics processing unit. Generalnie programujemy takie GPU: masz tu wierzchołki → musisz na nich zrobić takie przekształcenia matematyczne (vertex shader) → pokoloruj każdy pixel w zależności do jakiego obiektu należał dany fragment (fragment shader) → pokaż to na ekranie. Na rynku jest multum dostawców takich akceleratorów: Intel, AMD, nVidia, Snapdragon, Mali itd. I tu powstaje problem. Każdy dostawca sprzętu zaprojektował własny HW inaczej. Są podobne, bo do podobnych zadań to służy, ale jednak szczegóły są inne – inny programming model, inna ISA, inne charakterystyki (ilość bloczkó, które przetwarzają żądania). I w pewnym momencie przemysł IT doszedł do wniosku, że developer aplikacji nie powinien znać wszystkich szczegółów sprzętu i należy wprowadzić standard – API. Połączyli siły i powstała organizacja zwana Khronos Group zrzeszająca kluczowych graczy na rynku, którzy wprowadzili standard – OpenGL/Vulkan. To jest standard, który opisuje co należy zrobić, aby użyć danego akceleratora. Producenci zobowiązali się przestrzegać standardu (z tym jest różnie) i pisać do tego biblioteki – sterowniki, które będą tłumaczyć wysokopoziomowe zapytania OpenGL na polecenia do GPU, które ono rozumie. To pozwoliło pisać aplikacje raz i przenosić to na różne platformy/sprzęty. Powstały nawet testy certyfikacyjne, które mówią, że dany sprzęt spełnia warunki specyfikacji, do czego dąży każdy producent sprzętu, bo może dać naklejkę OpenGL 4.X compliant.
Jestem typowym linuxiarzem i skupię się na systemach Unixopodobnych, bo łatwo można znaleźć źródła, co umożliwi dalszą penetrację tematu.
3. Architektura OpenGL na Linuxie
Będę się skupiał na Linuxie i Intelu jako przykładzie. Wszystkie inne architektury są podobne, bo korzystają z tej samej infrastruktury oprogramowania open source. Jądro jest jedno, infrastruktura jest jedna – Mesa. Mesa jest projektem open source, który jest mocno rozwijany i jest zbiorem sterowników dla OpenGL / Vulkan / Vaapi dla różnych platform. Większość sterowników jest developowana przez producentó sprzętu. Wyjątkiem jest nVidia i Apple, którzy nie publikują własnych sterowników i pozostaje reverse engineering i próby implementacji sterowników przez hobbystów, którzy są opłacani przez zainteresowane strony.
Wracając do architektury. Wszystko o czym będę mówił jest publicznie dostępne i źródła są do pobrania i skompilowania.
Podstawowa architektura wygląda następująco:
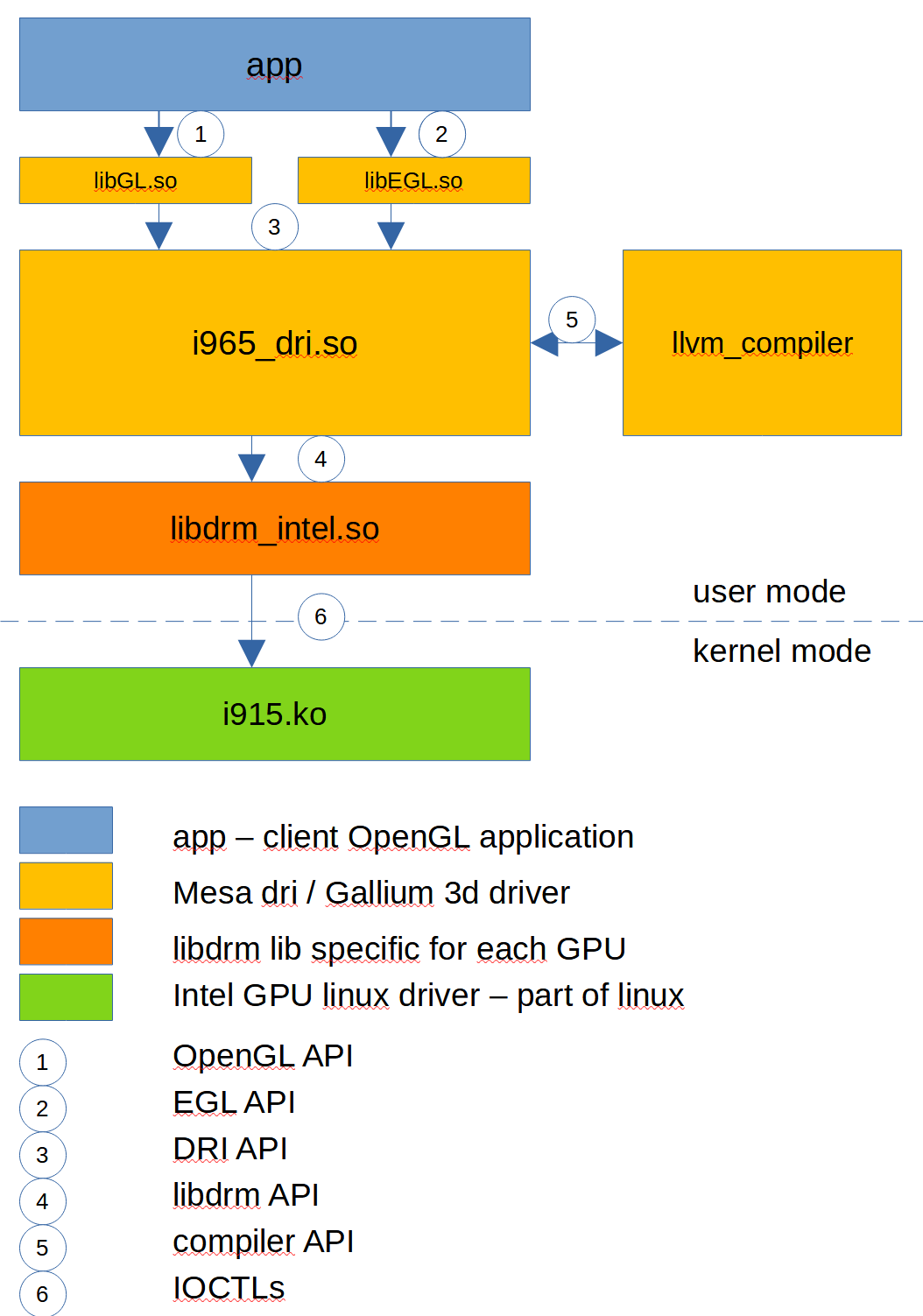
To co nas interesuje to prześledzenie ścieżki od aplikacji do HW. 2. aplikacja inicjalizuje sprzęt poprzez EGL API (tworzy okienko w uproszczeniu). Następnie zaczyna wołać różne funkcje OpenGL (sclearuj mi ekran na przykład na kolor niebieski). LibGL i libEGL są po to, aby obsłużyć te początkowe calle i dalej pobrać implementacje funkcji z konkretnego sterownika – w tym przypadku ze sterownika i965_dri.so, który odpowiada za programowanie sprzętu Intela. Komunikacja pomiędzy sterownikiem a libGL/libEGL odbywa się poprzez DRI API. Sterownik zbiera te calle, jeśli się trafił shader [to jest taki program napisany przez Developera, który pozwala na zrobienie odpowiednich obliczeń na GPU; jeśli to są przekształcenia współrzęncyh lokalnych na globalne, to jest to vertex shader, jeśli to jest kolorowanie fragmentu ekranu jest to fragment shader; jest dużo wierzchołków obiektu, dlatego należy to zrównoleglić i odpalić pierdyliard takich małych programików – shaderów – i to jest magia GPU; Pojedyncze GPU jest w stanie odpalić takich programikó bardzo dużo w tym samych czasie i zrobc obliczenia równolegle], to sterownik zawoła kompilator, który przetłumaczy tekst danego programu na assembler konkretnego GPU. W momencie gdy sterownik dostaje call OpenGL, to tłumaczy go na bity/bajty, które rozumie HW. HW nie rozumie OpenGLa, HW rozumie bity. Sterownik wysterowuje HW, żeby zrobiło mu dobrze (narysowało to co było wymagane). Sterownik konstruuje bufor, czyli obszar pamięci, w którym umieszcza te bity (zgodnie ze specyfikacją HW!!, bo inaczej może wszystko pójść w piach). Jak aplikacja skończy z jedną ramką, to sterownik poprzez api z libdrm wysyła bufor do kernela poprzez ioctl. Kernel mode driver – i915.ko – to jest rura, która wie jak po PCI wysłać dany bufor do HW, więc to czyni bez zawahania i wszystko jest zrobion.
Jaki jest problem z tym podejściem? Główny problem, że kontent od aplikacji, np. shadery może się różnić od ramki do ramki – następuje rekompilacja shaderów itd. Drugi problem sami Państwo rozumieją, że jeśli sterownik USB w kernelu daje ciała i powoduje problem, to nie możemy nic zrobić – cały kernel szlag trafia i trzeba zrestartować maszynę i naprawić USB. Czyli kernel mode driver jest uzależniony od innego sprzętu, który jest w maszynie.
4. Współpraca EGL z kompozytorem
No dobra. Narysowaliśmy coś w buforze, to znaczy GPU narysowała coś w obszarze pamięci, który jest HW local. Jak wyświetlić ten obszar pamięci na ekranie? Cóż, wystarczy wysłać numerek identyfikacyjny danego obszaru z naszej warstwy EGL do kompozytora, Kompozytor jest to aplikacja 3D, która zbiera takie numerki, otwiera je w kernelu, żeby one były widoczne w tym procesie i z różnych buforó od różnych aplikacji robi kompozycję ostatecznego obrazku na ekranie.
Jak to robi? Znowu poprzez OpenGL:

libEGL poprzez IPC – inter process communication – wysyła numerek do kompozytora, w tym momencie jest to Wayland / Xorg. Proszę zauważyć, że nie kopiujemy żadnych obszarów pamięci pomiędzy procesami – ot, wysyłamy numerek identyfikacyjny i gra gitara. Wayland „otwiera” w kernelu ten obszar pamięci i może użyć go jako tekstury do kompozycji. Finalny obrazek jest HW local, czyli jest w pamięci GPU i po HDMI jest wysyłąny na ekran.
5. Architektura OpenGL w wirtualnych maszynach
No dobra, a jeśli chcemy użyć OpenGL w wirtualnej maszynie?
Da się!
Można zrobić HW pass through, czyli przypisać wirtualnej maszynie konkretne zasoby na GPU i w samej wirtualnej maszynie można widzieć część GPU jako zasób do którego można wysyłać skonstruowane command bufory – to jest obszar pamięci z bitami ustawionymi konkretnie pod dane HW.
Ciekawym rozwiązaniem jest parawirtualizm OpenGL – VirGL. Gdzie maszyna wirtualna nie widzi prawdziwego HW, a tylko generyczne ustrojstwo. Architektura tego wygląda nasepująco:
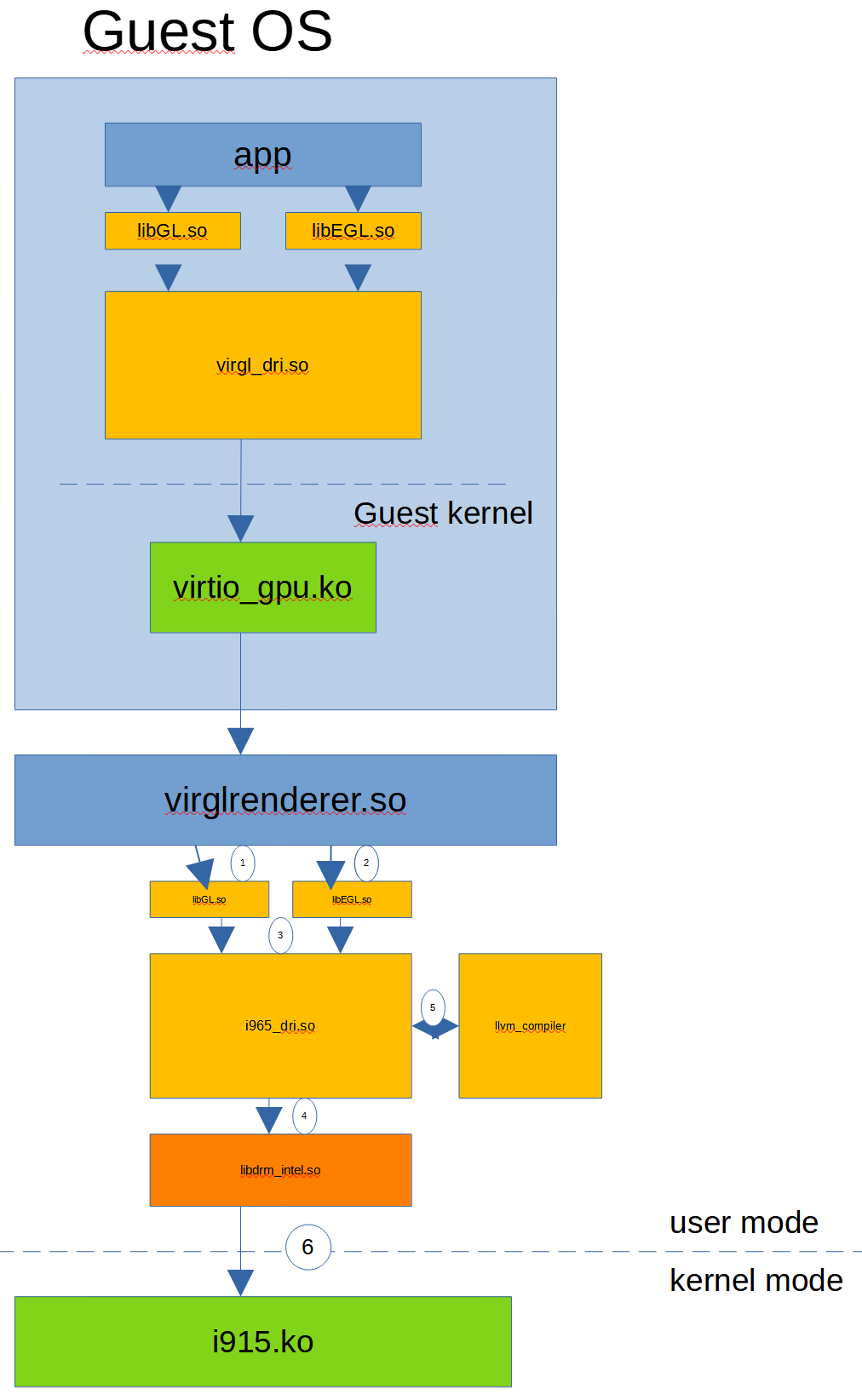
Aplikacja w wirtualnej maszynie normalnie woła calle OpenGL, Mesa i VirGL (kolejny sterownik w Mesie) tłumaczy to na bity z protokołu VirGL – konstruuje bufor z bitami, które opisują z grubsza co klient chciał zrobić. VirGL wysyła to do guest kernela, który obsługuje różne aplikacje z tej samej wirtualnej maszyny i przekazuje bufory do host OS. Mając dany bufor, który jest zapełniony informacją, co kliencka aplikacja chciała zrobić, to virglrenderer.so, może przetłumaczyć te informacje z powrotem do calli OpenGL i jako zwykły klient używa sterownika OpenGL do renderowania na ekran. Skomplikowane? Możliwe, ale to pozwala na posiadanie kilku wirtualnych maszyn naraz, które mogą używać OpenGL i HW w pełni zasobów.
6. Architektura OpenGL na Androidzie
Jak to się dzieje, że klikamy na telefonie w grę i gra, napisana w Javie potrafi użyć akceleracji 3D na telefonie, bo pamiętajmy, że każdy smartfon ma GPU na pokładzie.
Inżynierowie wymyślili takie cuś jak JNI – Java native interface. Z aplikacji w Javie można zawołać kod napisany w C / C++ bez problemu. Architektura tego wygląda tak:
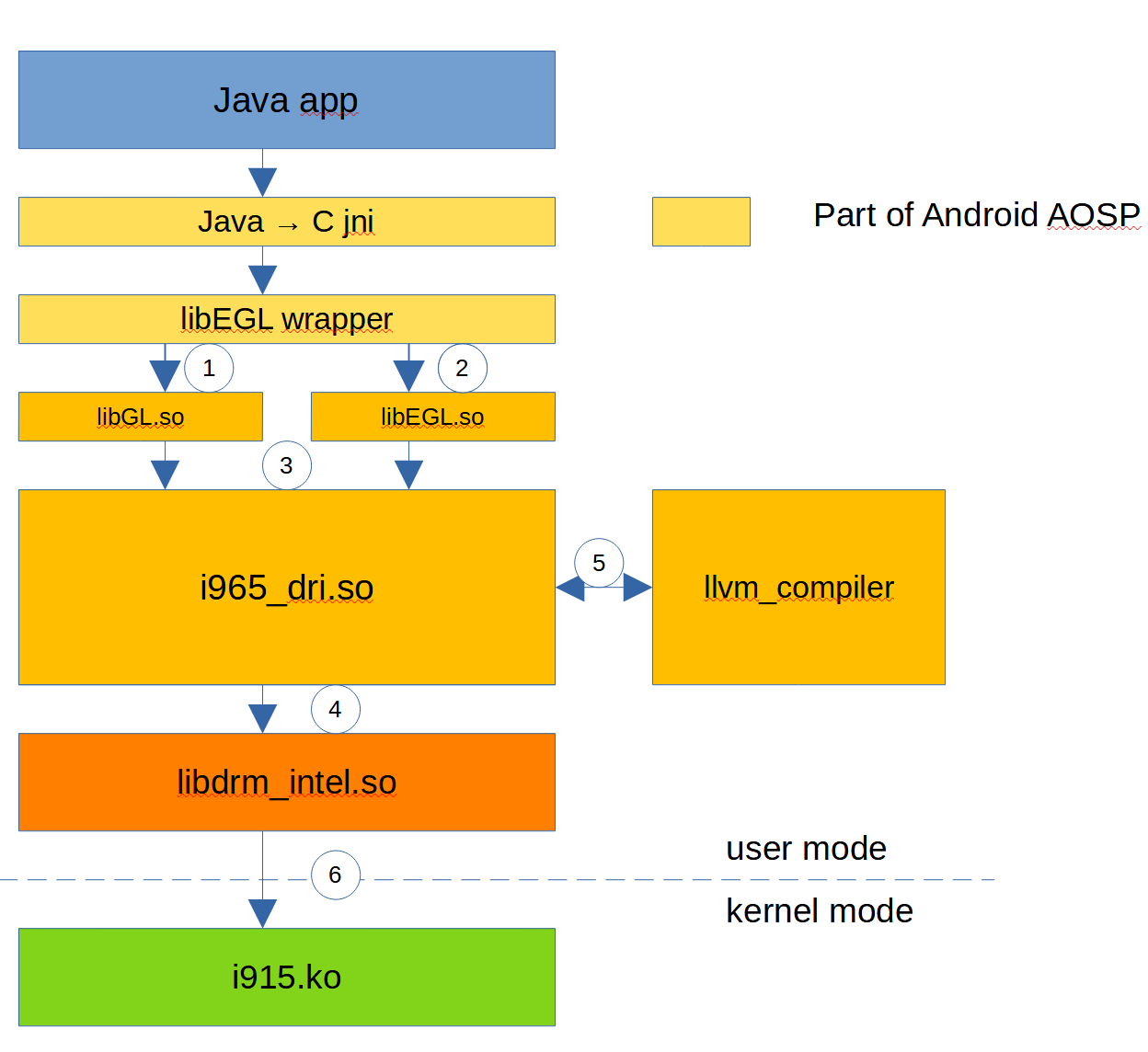
Tylko Android w celach trace-owania zachowań aplikacji wprowadził dodatkowo wrappery, które mogą być użyte do dodatkowych kogów z działąnia aplikacji.
7. Architektura OpenGL w Safety Critical systemach
No dobra, mamy to! Ostatni obrazek. Jak wspomniałem wcześniej, wszyscy lubimy Linusa, ale kernel Linuxowy nie jest Safety Critical w ogóle. Jeśłi coś się stanie sterownikowi USB i nagle przestaje działać, to przestaje działać cały kernel i nic nie możemy wyświetlić na ekranie! A w helikopterach bojowych jest to ważne! Pilot musi widzieć stan maszyny na ekranie, nawet jeśli słuchawki padły.
Do tego wprowadzono Safety Critical RTOS – Real Time OS. Różne firmy implementują to po swojemu. Generalnie jest w takim systemie tylko cienki kernelik, który głównie odpowiada za inicjalizację podstawową, a reszta kernel mode drivers została wyciągnięta za uszy w user space. To oznacza, że każdy sterownik do każdego urządzenia w systemie jest innym procesem i po prostu jeśli padnie, to inne peryferia mogą pracować dalej:
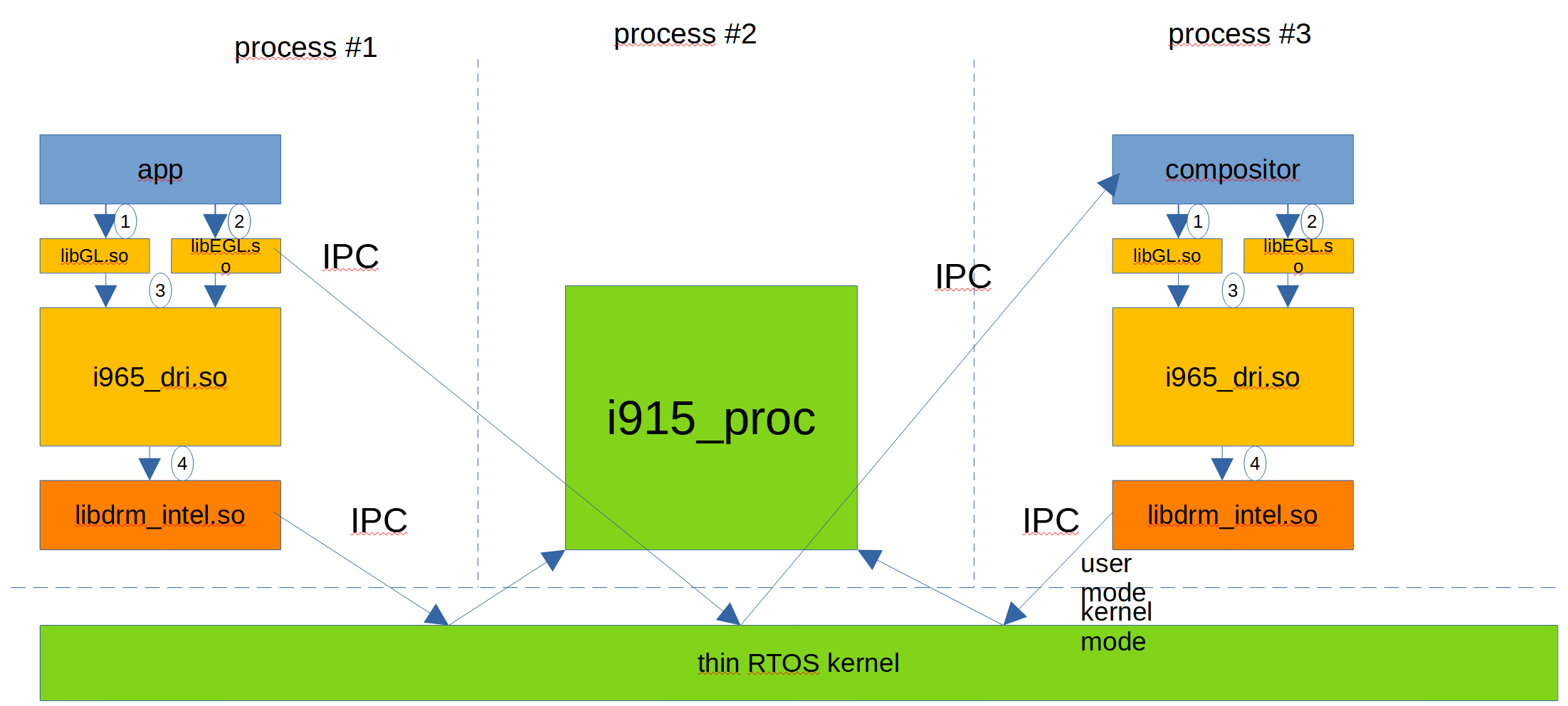
Uważny czytelnik dostrzegł, że wykastrowano kompilator shaderów ze schematu. A to oznacza, że go tam nie ma. Nie chcemy w Safety Critical urządzeniach dopuścić do tego, żeby aplikacja za każdym razem przekompilowywała nowe shadery – nie ufamy jej. Developer ma skompilować sobie na maszynie developerskiej shadery, przetestować i podać je jako binary blob do sterownika. Mniej wektorów ataku.
To by było na tyle.
Dziękuję za uwagę.